

I created a tool called WordPress Auto Publisher that extracts content from a Word document and uploads it to a user’s WordPress blog. One thing I had to include was extraction of images from a document to then upload to my customers’ blog, because images improve any blog post. I found lots of information about adding an image when building a docx document, but not a lot on extracting images and storing them to disk. I’ve decided to create a series of posts that help developers work with OpenXML, C# and Word files. This one will show you how to extract multiple images and save them to your hard drive.
Prerequisites
I’m using Visual Studio 2015, but this should work with any Visual Studio version. The great thing about OpenXML is that you don’t need Word or Microsoft Office installed on your computer to create docx files, extract any content, or edit documents. OpenXML treats Office documents as standard XML, except it has methods and properties specific to Office files.
You need the OpenXML Nuget package added to the references section of your project. Open Nuget Package Manager from the “Tools” menu and do a search for OpenXML. Install DocumentFormat.OpenXml by Microsoft in the list of Nuget packages and add the following using statements to your code file.
using DocumentFormat.OpenXml.Wordprocessing; using DocumentFormat.OpenXml.Packaging; using System.Drawing.Imaging; using System.IO; using System.Drawing;
The System.Drawing.Imaging package is not a part of OpenXML. It comes with .NET, but make sure System.Drawing is in the References section of your project. You’ll probably need to add it as a reference before you can use the library.
Microsoft Word and OpenXML Formatting
As of Office 2007, Microsoft stores files in XML. The XML can get pretty complex, but it’s basically your standard XML. A lot of times, you’d like to see the XML behind a Word document. There is a hack to see it.
- Make a copy of a Word document and store it on your hard drive.
- Rename the file and give it the extension “.zip.” (Windows will warn you about changing the extension, but change it anyway)
- Double-click the zip file, and open the “word” directory embedded in the zip file.
- Double-click the document.xml file to see the XML.
Here is a part of a Word document and its XML that has an embedded image.
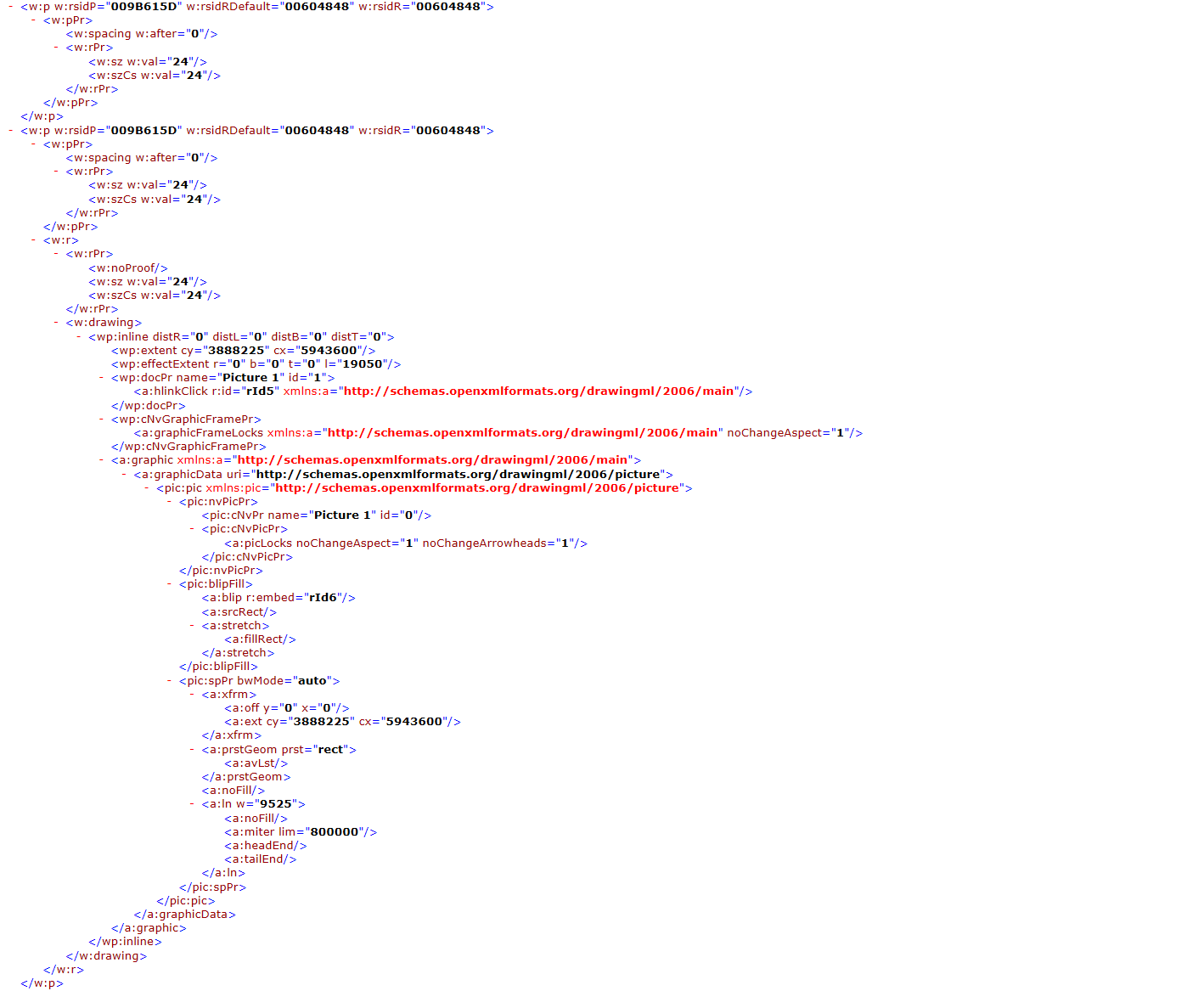
Before you can start programming with OpenXML, it’s important to know basic formatting. A Word document is broken down into paragraphs that are further made up of runs. Runs contain the content of a paragraph. One paragraph can be made up of several runs. For the most part, each run is composed of segments of formatted text. For instance, if you have two words in a paragraph and one is standard text and the other is bold text, there would be two runs in the one paragraph.
When you loop through and parse a Word document, you have two main loops. The outer loop goes through each paragraph, and the inner loop goes through each run within each paragraph. You then detect if any special component is included in the run such as an image, bold text, italic text, hyperlinks, etc. In this article, we’ll detect if there is an image in the run.
In the image above, you can see that we have two <w:p> tags. This is the tag for paragraphs. <w:r> is a run. We’ll get into the other formats in later series articles.
Extracting Images
For this example, I set up a WPF Windows desktop project and installed the Nuget OpenXML package from Microsoft. I created a button to initiate the extraction. Here is my button click event method.
private void button_Click(object sender, RoutedEventArgs e)
{
FileStream fs = new FileStream(System.IO.Path.GetDirectoryName(Process.GetCurrentProcess().MainModule.FileName) +
@"\TestFiles\testfileimage.docx", FileMode.Open);
Body body = null;
MainDocumentPart mainPart = null;
using (WordprocessingDocument wdDoc = WordprocessingDocument.Open(fs, false))
{
mainPart = wdDoc.MainDocumentPart;
body = wdDoc.MainDocumentPart.Document.Body;
if (body != null)
{
ExtractImages(body, mainPart);
}
}
fs.Flush();
fs.Close();
}
I’m using FileStream which is a part of the System.IO namespace. It opens the file for us, and then we can use the opened file and pass it to the WordprocessingDocument class. This loads it into a class that makes it much easier for you to parse through docx documents. The “GetDirectoryName” method gets the running application’s directory, so it doesn’t matter where this application runs. We can get the folder and files from the current directory and its subdirectories.
I assign the MainDocumentPart to the mainpart variable. MainDocumentPart is the entire XML for the entire document. It contains some extended properties, but we won’t need to worry about it in this article. This will be important in future articles in this series.
Think of the MainDocumentPart.Document.Body as the “body” of the XML document similar to the body of an HTML document. There are other properties, but this content contains all of the main text typed in the Word doc.
In this example, I’ve only opened one test document, but normally you would have a function that retrieves your Word documents in a folder, if you have more than one document that you need to parse. In this example, I’m using “\TestFiles\testfileimage.docx ” which has one image in it.
I’m passing these two objects to the ExtractImages function, which will be the heart of our extraction process.
Now let’s look at the ExtractImages method, which is where we do the actual extraction from the document’s XML.
private List<string> ExtractImages(Body content, MainDocumentPart wDoc)
{
List<string> imageList = new List<string>();
foreach (Paragraph par in content.Descendants<Paragraph>())
{
ParagraphProperties paragraphProperties = par.ParagraphProperties;
foreach (Run run in par.Descendants<Run>())
{
//detect if the run contains an image and upload it to wordpress
DocumentFormat.OpenXml.Wordprocessing.Drawing image =
run.Descendants<DocumentFormat.OpenXml.Wordprocessing.Drawing>().FirstOrDefault();
if (image != null)
{
var imageFirst = image.Inline.Graphic.GraphicData.Descendants<DocumentFormat.OpenXml.Drawing.Pictures.Picture>().FirstOrDefault();
var blip = imageFirst.BlipFill.Blip.Embed.Value;
string folder = System.IO.Path.GetDirectoryName(Process.GetCurrentProcess().MainModule.FileName);
ImagePart img = (ImagePart)wDoc.Document.MainDocumentPart.GetPartById(blip);
string imageFileName = string.Empty;
//the image is stored in a zip file code behind, so it must be extracted
using (System.Drawing.Image toSaveImage = Bitmap.FromStream(img.GetStream()))
{
imageFileName = folder + @"\TestExtractor_" + DateTime.Now.Month.ToString().Trim() +
DateTime.Now.Day.ToString() + DateTime.Now.Year.ToString() + DateTime.Now.Hour.ToString() +
DateTime.Now.Minute.ToString() +
DateTime.Now.Second.ToString() + DateTime.Now.Millisecond.ToString() + ".png";
try
{
toSaveImage.Save(imageFileName, ImageFormat.Png);
}
catch (Exception ex)
{
//TODO: handle image issues
}
}
imageList.Add(imageFileName);
}
}
}
return imageList;
}
You could have more than one image in a document, so the ExtractImages method is made to return a list of images file names. Since my file only has 1 image, only one is returned, but you could potentially have 10 images in a file. To extract them, you need to grab the images from the file and store them to the hard disk. After they are stored on your drive, you can manipulate them as if they were images stored on a user’s hard drive and never started out in a Word document.
Notice that we have two main foreach loops. The first one is to loop through paragraphs. Remember that paragraphs are the main components that are made up of runs. The first foreach loop goes through each paragraph, and within each paragraph the next foreach loop goes through each run.
The first thing we do when we drop into the run foreach loop is detect if it contains in image. We do this with this statement:
DocumentFormat.OpenXml.Wordprocessing.Drawing image = run.Descendants<DocumentFormat.OpenXml.Wordprocessing.Drawing>().FirstOrDefault();
By using the FirstOrDefault() method in LINQ, it will either return the first drawing in the run or return null. If no image is found, then the image variable will be null and the loop will skip to the next loop iteration.
The next lines of code are used to drill down into OpenXML’s complex structure to “find” the image and its name.
var imageFirst = image.Inline.Graphic.GraphicData.Descendants<DocumentFormat.OpenXml.Drawing.Pictures.Picture>().FirstOrDefault(); var blip = imageFirst.BlipFill.Blip.Embed.Value; string folder = System.IO.Path.GetDirectoryName(Process.GetCurrentProcess().MainModule.FileName); ImagePart img = (ImagePart)wDoc.Document.MainDocumentPart.GetPartById(blip);
Each image (and other Word components) have an Id. In this case, we can get the Blip Id value (used for images), and search for the image name using “GetPartById”. You’ll find that when you work with more complex formatting in Word documents that you’ll need to get the Id and then search the document properties that match the Id. Microsoft Word XML will have a list of Ids that match a property, and then you use this Id to figure out what format is being used. The Blip value in this example will return an Id that uniquely identifies this image. This Id is then used to query the document and extract the component. Each component Id has the format “rId<incremented number>”. In my example, the image has the id “rId5.” rIds are the main identifiers for each OpenXML part in your documents including PowerPoint presentations and Excel spreadsheets.
With this example, I’m just storing the image document in a subdirectory within my project, so I want to know the folder that’s running my program before I can save my image to a subdirectory, and I can do this with this line of code:
string folder = System.IO.Path.GetDirectoryName(Process.GetCurrentProcess().MainModule.FileName);
When you extract an image and store it to the hard drive, you need to give it a name. I give the image a name that corresponds with the date and time to ensure that no two images get the same name. By incorporating the time with milliseconds, it’s unlikely that our program will overwrite another image.
This statement sets up the image name.
imageFileName = folder + @"\TestExtractor_" + DateTime.Now.Month.ToString().Trim() + DateTime.Now.Day.ToString() + DateTime.Now.Year.ToString() + DateTime.Now.Hour.ToString() + DateTime.Now.Minute.ToString() + DateTime.Now.Second.ToString() + DateTime.Now.Millisecond.ToString() + ".png";
Now we just need to save the image to the hard drive. If you don’t specify format (in this case .png), you run the risk of receiving a GDI error when you save the file, so always specify the image format.
This using block sets up the image and saves it to disk.
using (System.Drawing.Image toSaveImage = Bitmap.FromStream(img.GetStream()))
{
imageFileName = folder + @"\TestFiles\TestExtractor_" + DateTime.Now.Month.ToString().Trim() +
DateTime.Now.Day.ToString() + DateTime.Now.Year.ToString() + DateTime.Now.Hour.ToString() +
DateTime.Now.Minute.ToString() +
DateTime.Now.Second.ToString() + DateTime.Now.Millisecond.ToString() + ".png";
try
{
toSaveImage.Save(imageFileName, ImageFormat.Png);
}
catch (Exception ex)
{
//TODO: handle image issues
}
}
The last section of the loop stores the image to the List<string> and returns it. You can then do anything you want with the image. In my WordPress Auto Publisher service, I use the list of images to upload to my customers’ WordPress blog.
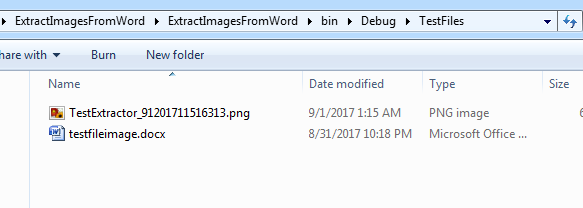
Just to verify, take a look at the TestFile directory and there is the Png extracted from our Word document.
Here is all of the code including the button event function and the main extraction function. More to come on OpenXML and C#.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
using System.IO;
using System.Drawing;
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Wordprocessing;
using System.Diagnostics;
using System.Drawing.Imaging;
namespace ExtractImagesFromWord
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
}
private List<string> ExtractImages(Body content, MainDocumentPart wDoc)
{
List<string> imageList = new List<string>();
foreach (Paragraph par in content.Descendants<Paragraph>())
{
ParagraphProperties paragraphProperties = par.ParagraphProperties;
foreach (Run run in par.Descendants<Run>())
{
//detect if the run contains an image and upload it to wordpress
DocumentFormat.OpenXml.Wordprocessing.Drawing image = run.Descendants<DocumentFormat.OpenXml.Wordprocessing.Drawing>().FirstOrDefault();
if (image != null)
{
var imageFirst = image.Inline.Graphic.GraphicData.Descendants<DocumentFormat.OpenXml.Drawing.Pictures.Picture>().FirstOrDefault();
var blip = imageFirst.BlipFill.Blip.Embed.Value;
string folder = System.IO.Path.GetDirectoryName(Process.GetCurrentProcess().MainModule.FileName);
ImagePart img = (ImagePart)wDoc.Document.MainDocumentPart.GetPartById(blip);
string imageFileName = string.Empty;
//the image is stored in a zip file code behind, so it must be extracted
using (System.Drawing.Image toSaveImage = Bitmap.FromStream(img.GetStream()))
{
imageFileName = folder + @"\TestFiles\TestExtractor_" + DateTime.Now.Month.ToString().Trim() +
DateTime.Now.Day.ToString() + DateTime.Now.Year.ToString() +
DateTime.Now.Hour.ToString() + DateTime.Now.Minute.ToString() +
DateTime.Now.Second.ToString() + DateTime.Now.Millisecond.ToString() + ".png";
try
{
toSaveImage.Save(imageFileName, ImageFormat.Png);
}
catch (Exception ex)
{
//TODO: handle image issues
}
}
imageList.Add(imageFileName);
}
}
}
return imageList;
}
private void button_Click(object sender, RoutedEventArgs e)
{
FileStream fs = new FileStream(System.IO.Path.GetDirectoryName(Process.GetCurrentProcess().MainModule.FileName) +
@"\TestFiles\testfileimage.docx", FileMode.Open);
Body body = null;
MainDocumentPart mainPart = null;
using (WordprocessingDocument wdDoc = WordprocessingDocument.Open(fs, false))
{
mainPart = wdDoc.MainDocumentPart;
body = wdDoc.MainDocumentPart.Document.Body;
if (body != null)
{
ExtractImages(body, mainPart);
}
}
fs.Flush();
fs.Close();
}
}
}
[…] the last article, I showed you how to extract images from a Word document. In this article, I’m going to use some of the same code and expand it to detect text […]
I don’t know what you’ve written this in, my boy,
(this is not C#: private List<string> ExtractImages(Body content, MainDocumentPart wDoc))
but the image handling idea is correct
bah thank you for pointing that out. Looks like my host move encoded the HTML characters -_- Guess I have a fix to do soon. Thanks again for letting me know.
Well thought out and well explained. Thanks a lot, man.
Thank you, Jennifer! Very well written. Saved me a lot of time figuring this out.
You’re welcome. I’m glad it helped you> 🙂
Thanks.
Is it possible while getting the images for saving – to delete it from the document and inserting a text instead, something like “<>”, for all the images?
hi Yeshurun, it’s been a while since I wrote this and did it in code, but I assume you could this since it’s just a change of the underlying xml but don’t quote me on that since I have not messed with this procedure in a while 🙂
Thank you for your kind reply. Found it a bit complicated to manage the document with OpenXml, and there’s a real lack of explanation around. All the best.